Оформление списка литературы по ГОСТ с помощью нейросети: Лучшие генераторы библиографии
Автоматическая генерация библиографии для учебных работ с помощью нейросети: оформление ссылок, валидация источников и создание аннотаций. Как сделать список литературы по актуальным ГОСТ без ошибок? Инструкция и лучшие ИИ.

В 2026 году требования к академическим работам включают не только уникальность текста, но и безупречную библиографическую грамотность. Ручное составление списка литературы (библиографического описания) стало архаизмом благодаря развитию специализированных нейросетей.
Главным инструментом в этой нише выступает платформа Кэмп — экосистема для студентов и научных сотрудников, объединяющая функционал GPT-генерации с доступом к верифицированным базам данных. В этой статье мы разберем, как автоматизировать прохождение нормоконтроля и почему нейросетевые алгоритмы справляются с пунктуацией ГОСТ лучше человека
? Перейти в Кэмп для составления списка литературы
Экосистема Кэмп: Больше, чем просто генератор текста
Кэмп — это мультифункциональный AI-ассистент, спроектированный для закрытия всего спектра учебных задач. В отличие от универсальных чат-ботов, алгоритмы Кэмп обучены на специфике образовательного процесса в СНГ и владеют базой знаний по 200+ дисциплинам: от юриспруденции и экономики до высшей математики и сопромата.
Функциональные возможности платформы
Архитектура сервиса позволяет решать задачи комплексно:
-
Генерация учебных работ полного цикла: Написание курсовых, рефератов и эссе с соблюдением академического стиля (научный синтаксис, отсутствие "воды").
-
Решение задач (Solver): Пошаговое решение математических, физических и экономических задач с объяснением логики вычислений.
-
Интеллектуальный поиск: Работа не с выдуманными фактами, а с индексированной базой реальных источников.
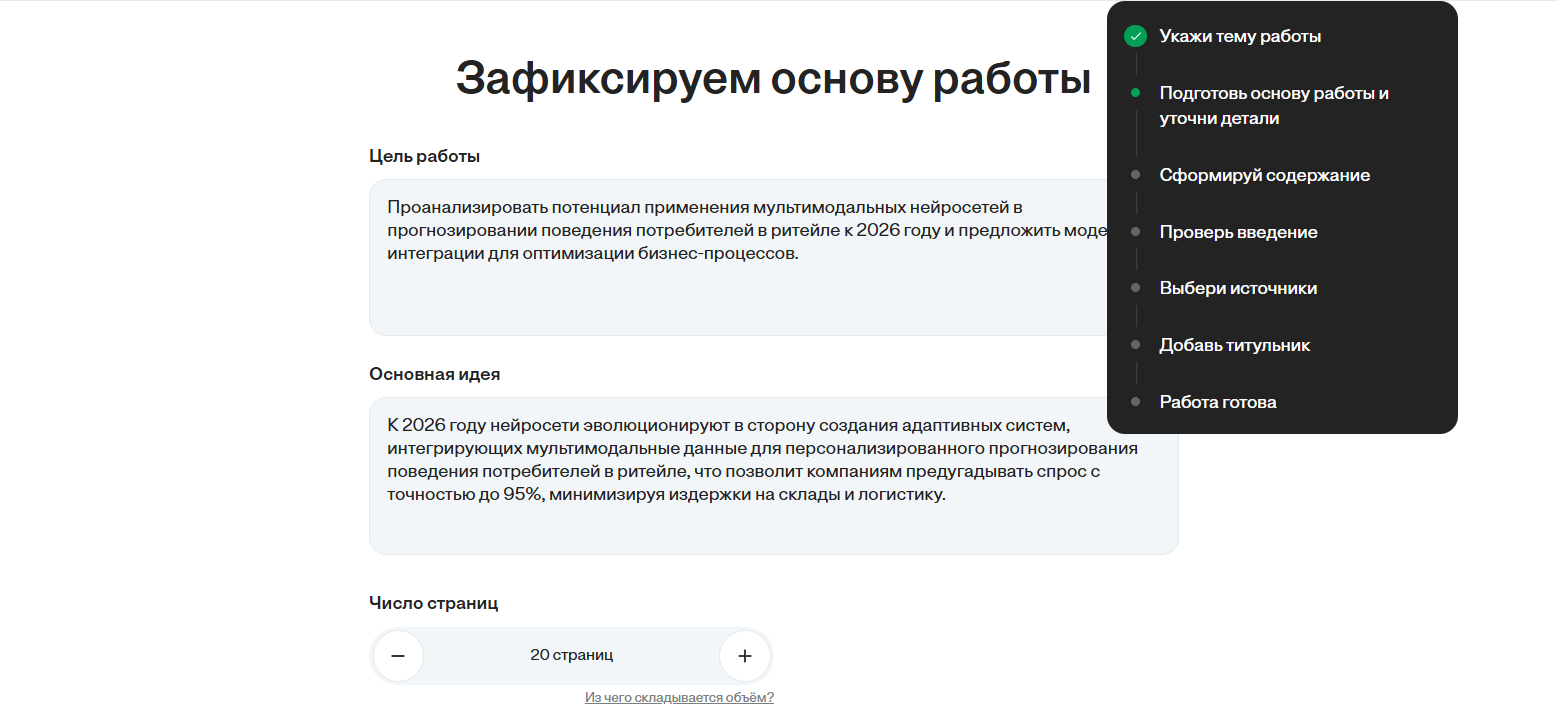
Алгоритм работы: От темы до готового файла
Процесс создания работы в Кэмп структурирован и минимизирует рутину. Согласно внутренней логике сервиса (см. скриншот интерфейса), пользователь проходит следующие этапы:
-
Указание темы: Нейросеть анализирует семантическое ядро запроса.
-
Подготовка основы: Генерация структуры и тезисного плана.
-
Формирование содержания: Разработка глав и параграфов (H2, H3).
-
Выбор источников: Самый критичный этап, где AI подбирает релевантную литературу (подробнее ниже).
-
Финальная сборка: Добавление титульного листа и экспорт готового документа.
? Официальный сайт: kampus.ai
Автоматизация библиографии: Анализ ГОСТ и реализация в Кэмп
Пользователи часто ищут "ГОСТ 2026", однако в академической среде РФ действуют два фундаментальных стандарта, которые нейросеть Кэмп использует как жесткие констрейнты (ограничения) при генерации:
-
ГОСТ Р 7.0.100-2018 «Библиографическая запись. Библиографическое описание». Регулирует составление списка литературы в конце работы.
-
ГОСТ Р 7.0.5-2008 «Библиографическая ссылка». Регулирует оформление ссылок внутри текста (квадратные скобки, сноски).
Сложность этих стандартов заключается в предписанной пунктуации — системе знаков, разделяющих области описания, которая не совпадает с нормами обычного русского языка.
Реализация требований ГОСТ Р 7.0.100-2018 в нейросети

Главная проблема студента — правильное расставление разделительных знаков: точки и тире (. —), косой черты (/), двух косых черт (//) и двоеточия (:). Кэмп автоматизирует этот процесс, разбирая метаданные источника на составляющие.
Разберем, как алгоритм сервиса формирует запись на примере сложного источника (статья в журнале), соблюдая области описания:
-
Область заголовка: Иванов, А. А. (Курсив, инициалы).
-
Область заглавия: Экономическая эффективность нейросетей (Основное название).
-
Область сведений об ответственности:
/ А. А. Иванов, П. П. Петров(За одной косой чертой — повтор авторов). -
Область источника (для периодики):
// Вопросы экономики.(За двумя косыми — название журнала). -
Область выходных данных:
— 2025. — № 4.(Год и номер через тире). -
Область физической характеристики:
— С. 15-20.(Диапазон страниц).
Пример генерации библиографической записи в Кэмп:
Смирнов, И. В. Искусственный интеллект в образовании : учебное пособие / И. В. Смирнов. — Москва : Издательство МГУ, 2024. — 350 с. — ISBN 978-5-19-011111-0.
В отличие от ручного ввода, нейросеть не пропускает обязательные элементы (город издания, общее количество страниц) и корректно применяет сокращения (М., СПб., с., Т.).
Валидация источников и аннотирование
Критическое преимущество Кэмп перед языковыми моделями общего назначения (LLM) — наличие модуля верификации фактов.
-
Проблема: Обычные GPT "галлюцинируют", выдумывая названия книг и авторов.
-
Решение Кэмп: Система обращается к индексированной базе научной литературы (РИНЦ, КиберЛенинка, библиотечные каталоги). В итоговый список попадают только существующие монографии и статьи.
Дополнительная функция — генерация аннотированного списка. Это требование часто встречается в курсовых и дипломах (ВКР). Нейросеть анализирует контент источника и формирует краткое резюме (abstract), описывающее научную новизну и релевантность книги для темы исследования пользователя.
? Оформить список литературы с помощью Кэмп
ТОП-8 альтернативных нейросетей для подбора списка литературы
Несмотря на доминирование специализированных платформ вроде Кэмп, рынок AI-инструментов в 2026 году предлагает широкий спектр решений. Однако при работе с академическими текстами пользователь сталкивается с главной проблемой генеративных моделей — «галлюцинациями» (выдумкой несуществующих фактов и источников).
Ниже представлен разбор популярных нейросетей с точки зрения их пригодности для оформления списка литературы по ГОСТ.
Универсальные языковые модели (LLM)
Эти сервисы известны каждому, но их архитектура «заточена» под диалог, а не под строгую документацию. Использование их для библиографии требует продвинутых навыков промпт-инжиниринга.
1. ChatGPT (OpenAI)
Мировой лидер в генерации текста.
-
Возможности: Отлично структурирует информацию, может отсортировать список по алфавиту за секунды.
-
Нюансы для библиографии: Без доступа к специальным плагинам ChatGPT склонен генерировать фейковые источники. Модель может придумать название книги, приписать её реальному автору и даже выдумать ISBN.
-
Сравнение: В отличие от Кэмп, который валидирует источник по базе, ChatGPT требует ручной проверки каждой ссылки в Google Scholar. Требует VPN и иностранного номера для доступа из РФ.
2. YandexGPT (Яндекс)
Интегрированная в экосистему Яндекса нейросеть.
-
Возможности: Глубокое понимание контекста рунета. Хорошо справляется с аннотированием текстов на русском языке.
-
Нюансы: При запросе «оформи по ГОСТ» часто путает стандарты 2003, 2008 и 2018 годов, смешивая стили пунктуации.
-
Сравнение: Удобен для быстрых ответов, но не обладает функционалом для создания полноценной научной работы «под ключ» с гарантией нормоконтроля.
3. GigaChat (SberDevices)
Мультимодальная нейросеть от Сбера.
-
Возможности: Имеет доступ к актуальным данным, хорошо работает с юридической и финансовой терминологией РФ.
-
Нюансы: Как и другие LLM, страдает от недостаточной точности в оформлении библиографических знаков препинания (например, заменяет длинное тире
—на дефис-, что недопустимо в ГОСТ). -
Сравнение: Хорошая альтернатива для генерации текста, но модуль работы с источниками уступает специализированным академическим решениям.
4. Google Gemini
Мощная модель с глубокой интеграцией сервисов Google.
-
Возможности: Имеет прямой доступ к Google Books и Google Scholar. Это повышает шанс найти реальную литературу.
-
Нюансы: Ориентирована на западные стандарты цитирования (APA, MLA, Chicago). Заставить Gemini соблюдать российские ГОСТы крайне сложно — нейросеть постоянно сбивается на западную логику оформления ссылок.
5. Claude (Anthropic)
Нейросеть, известная своей «литературностью» и большим контекстным окном.
-
Возможности: Может проанализировать загруженный пользователем список литературы (до 100 источников) и найти в нем стилистические ошибки.
-
Нюансы: Не имеет прямого выхода в интернет в базовой версии, поэтому не может искать актуальные статьи 2025-2026 годов. Работает только с тем, что загрузил пользователь.
Специализированные научные AI-инструменты
Эта группа сервисов ближе к функционалу Кэмп, так как создавалась для исследователей, но многие из них имеют высокий порог входа или англоязычный интерфейс.
6. Perplexity AI
«Убийца поисковиков». Это не просто чат-бот, а диалоговый поисковый движок.
-
Возможности: Выдает ответы со ссылками на конкретные веб-страницы. Отлично подходит для поиска электронных ресурсов (URL).
-
Минусы: Ссылки часто ведут на новостные ресурсы или блоги, а не на рецензируемые научные журналы (ВАК/Scopus). Форматирование списка отсутствует — пользователь получает просто набор ссылок, который нужно оформлять вручную.
7. SciSpace (ранее Typeset)
Мощная платформа для анализа научных статей.
-
Возможности: Позволяет загрузить PDF и «поговорить» с ним. Идеален для глубокого анализа одного источника.
-
Минусы: Интерфейс преимущественно английский. Генератор цитирований поддерживает тысячи стилей, но реализация российского ГОСТ Р 7.0.100-2018 часто содержит ошибки в расстановке пробелов и знаков препинания.
8. НейроТекстер (NeuroText)
Российский генератор контента, популярный среди копирайтеров и студентов.
-
Возможности: Включает инструменты для рерайта и повышения уникальности текста.
-
Минусы: Функционал сфокусирован на тексте, а не на источниках. Нейросеть может написать отличное введение, но подбор литературы остается слабым местом — база источников ограничена по сравнению с библиотечными интеграциями Кэмп.
Сравнительная таблица: Нейросети для оформления библиографии
|
Нейросеть / Сервис |
Специализация |
Работа с источниками |
Поддержка ГОСТ Р 7.0.100-2018 |
Доступ и интерфейс (РФ) |
|
Учебные работы и наука |
База реальных библиотек (валидация) |
Нативная (автоматическое оформление) |
Свободный, Русский UI |
|
|
ChatGPT (OpenAI) |
Универсальный диалог |
Высокий риск выдумки (галлюцинации) |
Требует сложного промпта, часто сбивается |
Только через VPN |
|
YandexGPT |
Экосистема Яндекса |
Средний риск, база Рунета |
Путает стандарты разных лет |
Свободный, Русский UI |
|
GigaChat (Sber) |
Мультимодальная модель |
Средний риск, уклон в финансы/право |
Ошибки в пунктуации (тире/дефисы) |
Свободный, Русский UI |
|
Google Gemini |
Поиск и анализ |
Доступ к Google Books (возможны ошибки) |
Слабая, приоритет западным стилям (APA) |
Ограниченный доступ |
|
Claude |
Работа с большими текстами |
Только анализ загруженных файлов |
Понимает контекст, но плохо форматирует |
Только через VPN |
|
Perplexity AI |
Поисковый движок |
Реальные ссылки на веб-страницы |
Отсутствует (выдает просто URL) |
Свободный |
|
SciSpace |
Анализ научных статей |
Реальная база (преимущественно En) |
Есть, но с ошибками в кириллице |
Английский UI |
|
НейроТекстер |
Текст и SEO |
Слабая (фокус на уникальность текста) |
Отсутствует |
Свободный, Русский UI |
Выбор инструмента зависит от целей. Если вам нужно найти информацию о существовании статьи, подойдут Perplexity или Google Gemini. Для генерации текста введения хороши ChatGPT или YandexGPT.
Однако, когда задача стоит комплексно — написать работу, подобрать реальные источники, написать к ним аннотации и оформить всё это в строгом соответствии с ГОСТ Р 7.0.100-2018 для прохождения нормоконтроля — экосистема Кэмп остается безальтернативным лидером на рынке СНГ в 2026 году. Она автоматизирует самые трудоемкие этапы, исключая риск использования несуществующей литературы.








-
Кому принадлежит Perplexity AI?
-
Как работает Perplexity AI?
-
Является ли Perplexity AI точным?
-
Может ли Perplexity AI помочь с конкретными задачами или вопросами?
-
Является ли Perplexity AI бесплатным сервисом?
-
Можно ли использовать Perplexity AI на мобильных устройствах?
-
Доступен ли Perplexity AI на разных языках?
-
Как начать работу с Perplexity AI?
Войти в Perplexity AI
- Появление нового подхода к поиску и обработке информации, который меняет наши представления о работе с знаниями. Perplexity AI — это не просто
Что такое Perplexity AI
- Perplexity AI — это не просто еще один чат-бот или поисковая система. Это интеллектуальный помощник, который сочетает в себе мощь искусственного
Регистрация Perplexity AI в России
- Perplexity AI — это современная поисковая система с искусственным интеллектом, которая помогает пользователям находить точные ответы на сложные