ИИ-агенты: как мы сделали DeepResearch по корпоративным данным и кодовой базе
ИИ‑агенты — очень горячая тема. Кажется, все их делают, но также кажется, что реальную пользу приносит только небольшая часть. Один из основных удачных примеров — DeepResearch, глубокий поиск, отвечающий на сложные вопросы. Многие им пользуются в ChatGPT или Perplexity, но у внешних решений нет доступа к нашим корпоративным данным, поэтому мы сделали свой DeepResearch и сэкономили время сотрудников компании.
Меня зовут Сергей Скородумов, я руководитель отдела поисковых сервисов. В статье расскажу про ИИ‑агентов в целом, как мы делали своего, за счёт чего растили его качество и какие главные выводы сделали.
Краткий экскурс в историю ИИ-агентов
Вна��але было слово. А точнее, классическая LLM — модель, которая не ходила в поиск и не запускала внешние инструменты. Она отвечала только на основе того, что уже зашито в её параметры. У таких моделей всегда есть отсечка по времени знаний: например, «до 2021 года» и всё, что произошло позже, модель просто не знает — эти факты не включены в её веса.
Потом появился RAG — Retrieval‑Augmented Generation. Идея оказалась простой, но прорывной: пользователь задаёт вопрос, модель немного переформулирует его и отправляет в поиск. Затем она берёт тексты найденных страниц и на их основе формирует ответ.
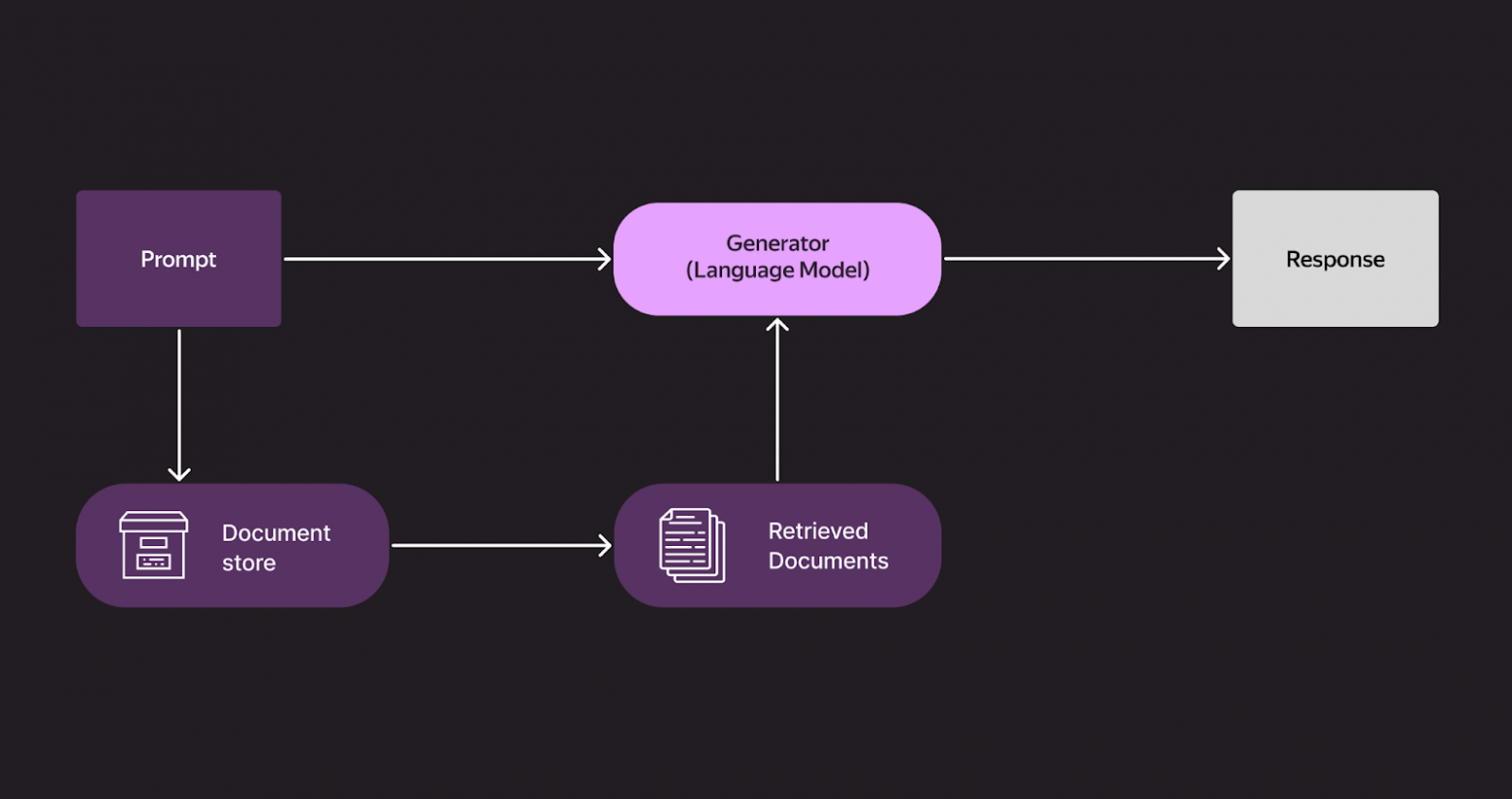
Так пользователи стали получать информацию о свежих событиях — матчах, релизах, обновлениях, даже если модель изначально обучалась на данных двухлетней давности.
Со временем RAG эволюционировал в более сложные конструкции — то, что сейчас часто называют AI workflow. Это уже набор связанных нод и правил: одна нода переформулирует запрос, другая запускает поиск (иногда несколько раз), третья читает документы, четвёртая решает, достаточно ли информации, а пятая может снова запустить поиск, если данных не хватает. Важно: эти шаги жёстко зашиты разработчиком, и модель следует по заранее описанному маршруту.
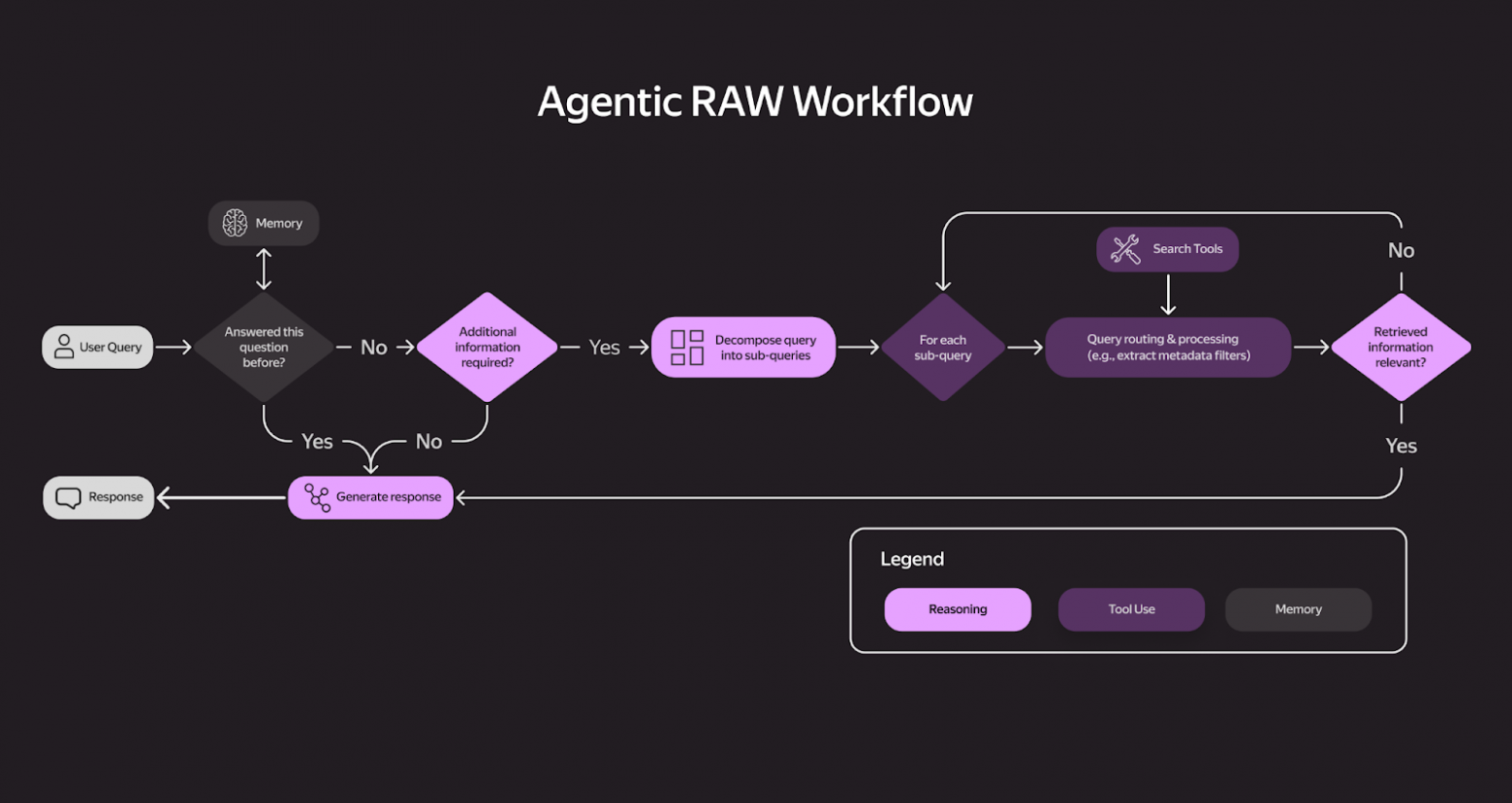
И вот мы пришли к следующему этапу — ИИ‑агенту. У него уже нет фиксированных правил, ему дают набо�� инструментов, и он сам решает, в какой последовательности и как их использовать. У него гораздо больше свободы, но он всё равно действует в рамках системного промпта или дообучения, которое ему задают.
Нейросети уже давно могут отвечать текстом, работать с изображениями, но теперь на первый план выходят ИИ‑агенты, которые могут выполнять ряд действий самостоятельно, — в том числе те, которые умеют писать код. Они берут задачу на вход, генерируют решение, тестируют его и при необходимости исправляют ошибки. Я сам пользуюсь такими инструментами: ставишь задачу — и получаешь рабочий код быстрее, чем если бы писал его вручную. Ошибки, конечно, бывают, но общий цикл разработки становится значительно короче.
Что такое DeepResearch и зачем нужно разрабатывать свой
DeepResearch отличается от обычного RAG тем, что не ограничивается принципом «задал запрос — получил результаты — отдал ответ». Он умеет анализировать множество страниц, делать дополнительные поисковые запросы, если информации не хватает, и выполнять серию промежуточных шагов, проверок и уточнений.
Один из первых таких режимов появился у ChatGPT, а похожие решения сейчас есть у Perplexity и Gemini, а также в Алисе AI для первых пользователей. Режим предназначен для глубокой исследовательской работы: достаточно задать Алисе AI цель исследования и описать его детали, а нейросеть сама составит план исследования, сделает десятки поисковых запросов по каждой теме, проанализирует сотни источников информации и скачает необходимые документы.
Такая схема особенно полезна, когда задаётся сложный вопрос, на который нельзя ответить одним поисковым запросом. DeepResearch экономит время, формирует развёрнутые, аргументированные ответы и помогает быстро погрузиться в незнакомую тему. Я сам регулярно пользуюсь DeepResearch для внутренних задач в Яндексе. Для этого у нас есть своя версия — Deep Agent Yandex Team Ru, доступная только сотрудникам.
Мой личный критерий того, что компании пора заводить собственный DeepResearch, очень простой: если вы сталкиваетесь с тем, что ChatGPT «не в курсе» внутренних дел компании, — значит, время пришло. Во многих средних и крупных организациях это неизбежно: знания разбросаны по Вики, внутренней документации, почте, чатам — и всё это недоступно внешним моделям. Поэтому корпоративный DeepResearch становится необходимостью.
Спустя три месяца после внедрения, эффект был очевидет. Время, которое раньше уходило на поиск информации, сократилось в несколько раз. Я в Яндексе уже семь лет, и раньше, чтобы ответить на внутренний вопрос, я тратил в среднем 10–20 минут, вручную копаясь в Вики и поиске. Теперь DeepResearch справляется с тем же за 30–60 секунд — и при этом качество ответа сравнимо с тем, что я получал, тщательно просматривая документы сам. Таких операций — сотни и тысячи ежедневно. По нашим подсчетам, внедрение ИИ‑агента уже дает экономию порядка 240 рабочих часов в день — ресурс, который команды теперь направляют на более сложные и творческие задачи.
Как мы делали свой DeepResearch
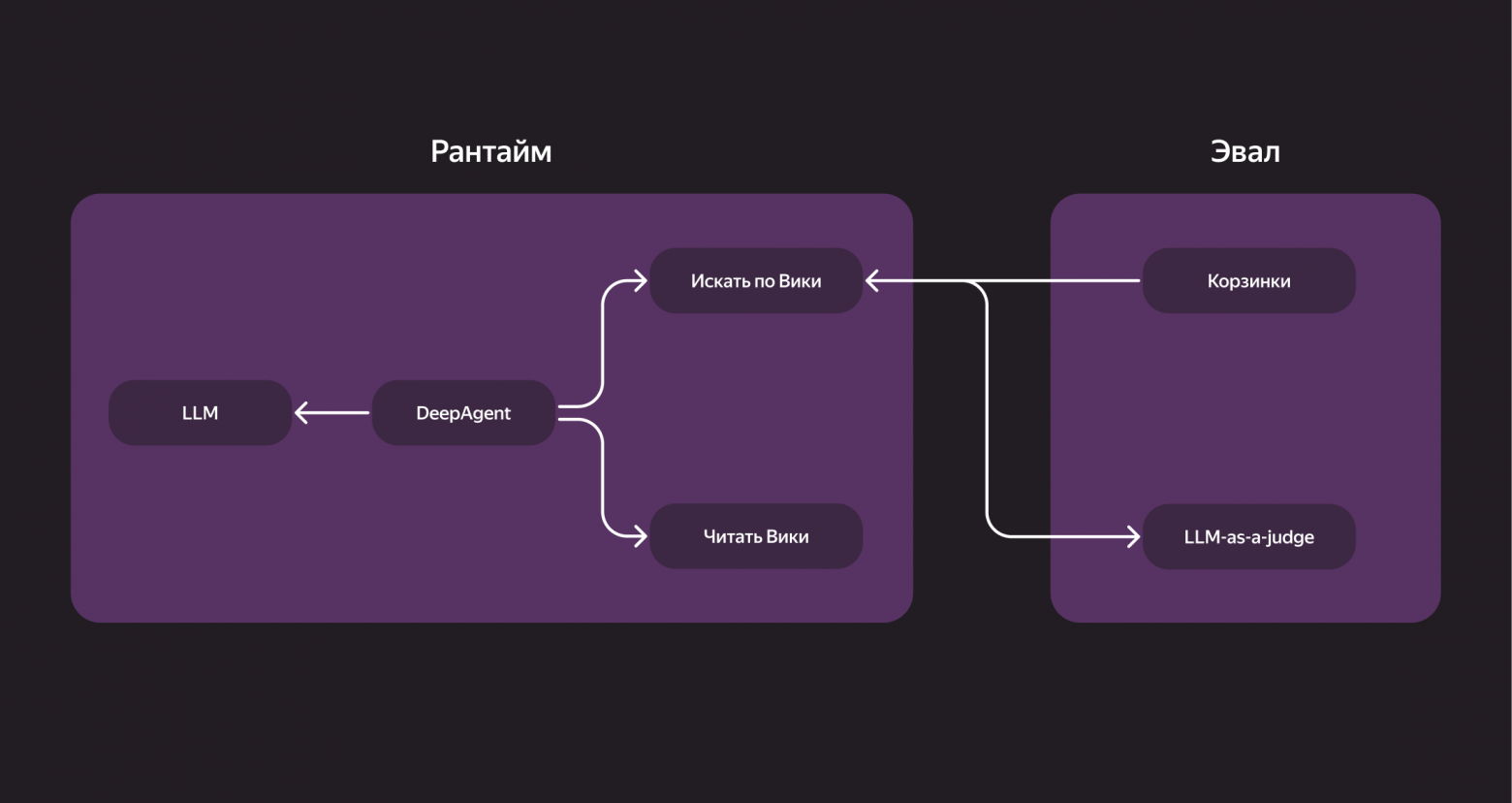
Начиналось всё максимально просто. Первую версию я собрал буквально за пару дней «на коленке»: в ней скрипт делал запросы во внутреннюю Вики, читал страницы и пытался собрать ответ. Работало, мягко говоря, посредственно, но этого хватило, чтобы проверить идею. Иногда можно было попасть на интересный, сложный вопрос, на который агент давал действительно хороший ответ. Но в среднем — отвечал плохо.
Как это было устроено технически: наш бэкенд‑DeepAgent обращался к локально поднятому поиску. Мы передавали ему инструкции вроде: «Вот, у тебя есть инструмент для поиска по Вики, можешь читать страницы — действуй, отвечай на вопросы». Дальше агент искал нужные документы, читал их и формировал ответ.
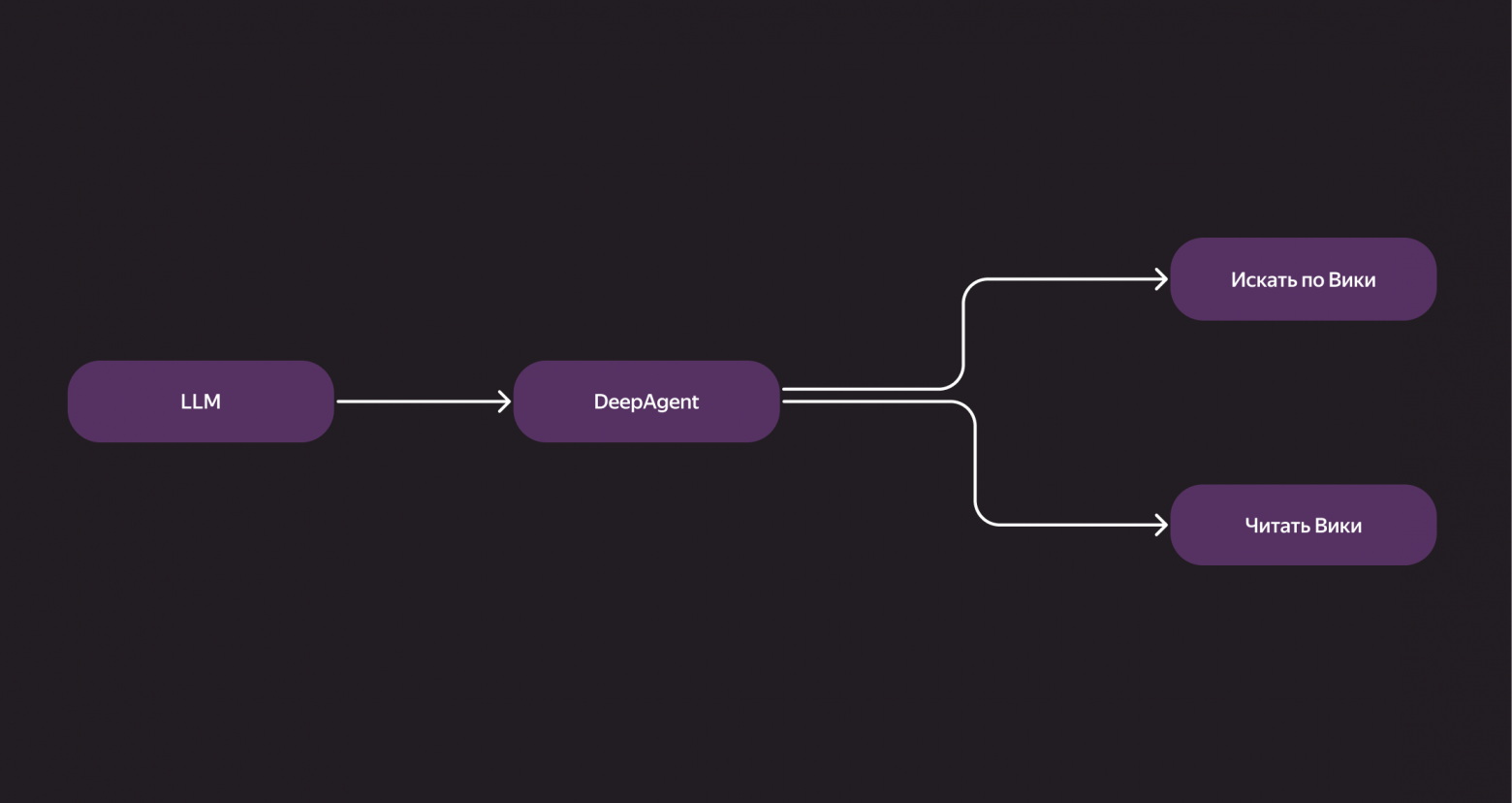
При этом мы осознанно не пошли по пути жёстко прописанных workflow, а вместо этого дали агенту довольно большую свободу действий. Мы подсказывали ему, как лучше работать, через систем‑промпт — но решение, идти ли сразу к ответу или запускать поиск, агент принимал сам. Если ответ уже был в запросе или на прикреплённой странице — он отвечал прямо. Если информации не хватало — шёл вглубь. Мы верили, что такая гибкость в долгосрочной перспективе даст лучший результат. Так и вышло.
Небольшой совет: если вы только начинаете делать свой DeepResearch, не стартуйте с мультиагентной архитектуры. Да, сейчас это модно: все хотят написать в резюме, что сделали систему, где 20 агентов координируются между собой, но на практике это только усложняет работу.
Я отношусь к мультиагентности как к микросервисной архитектуре: если у вас есть две независимые команды, которым действительно нужно взаимодействовать, — отлично, пусть у каждой будет свой агент, и они общаются по протоколу agent‑to‑agent. Но если вы решаете конкретную задачу одной командой — сосредоточьтесь на одном агенте. Потом, когда он стабильно заработает, можно думать о масштабировании.
Самое важное правило: всегда проводить оценку работы агента. А чтобы понимать, как он прогрессирует, нужны «корзинки» — тестовые наборы вопросов с ожидаемыми ответами.
Мы сделали два уровня:
-
Простые корзинки — где ответ можно найти на первой странице Вики.
-
Сложные корзинки — занимают у человека 20–60 минут на ручной поиск и проверку.
На сложных задачах мы, конечно, не получали стопроцентных результатов, но именно они показывали, насколько система приближается к уровню живого разработчика.
Для оценки ответов мы использовали подход LLM‑as‑a-judge — большая модель проверяла результаты автоматически. Но и саму «судью» мы регулярно перепроверяли вручную, чтобы убедиться, что она оценивает адекватно. Совет простой: всегда держите свои корзинки под рукой — без них невозможно объективно измерять прогресс.
Сложные корзинки мы делили на два типа:
-
Реальные вопросы из чатов и поддержки. Например: «Как починить баг B в сервисе C?» В чате знающий человек ответит минут за 10. А вот у новичка, который не знает ни кода, ни контекста, на это может уйти час.
-
Вопросы по коду. Пример: «Как устроена авторизация пользователя в сервисе D?» Иногда это были даже метавопросы — вроде «Как устроена авторизация в самом DeepAgent». Агент должен был пройти по огромному репозиторию, разобраться, где что вызывается и как всё работает.
А репозиторий у Яндекса действительно немал: компании уже 28 лет, кодом занимаются сотни разработчиков. Кода столько, что в контекст одной LLM он просто не влезет, даже частично — да и служба безопасности, понятно, не разрешит.
Так постепенно DeepAgent вырос до полноценного инструмента. Появились эвали, корзинки, LLM‑as‑a-judge. После каждого изменения мы проверяли качество — хотя бы не стало ли хуже, а лучше стало ли. И только благодаря этому циклу «изменил — проверил» мы вообще понимали, что движемся в правильном направлении.
Как мы растили качество DeepAgent
Когда базовые функции агента уже работают, возникает главный вопрос: как повышать его качество? Обычно для этого нанимают асессоров — они собирают датасеты, оценивают ответы и помогают модели учиться. Но в случае с DeepResearch этот подход не работает. Асессоры не знают внутренней инфраструктуры компании, не разбираются в коде и не понимают контекста внутренних процессов. Поэтому корзинки с данными пришлось собирать внутри — силами самих сотрудников.
Первые вопросы и ответы команда написала вручную, а потом стала искать источники данных: внутренние саппорт‑чаты, корпоративный Stack Overflow, Вики, документацию, README‑файлы и даже открытые фрагменты переписок в телеграм‑чатах (где нет приватных данных). Этот шаг неожиданно дал заметный прирост качества.
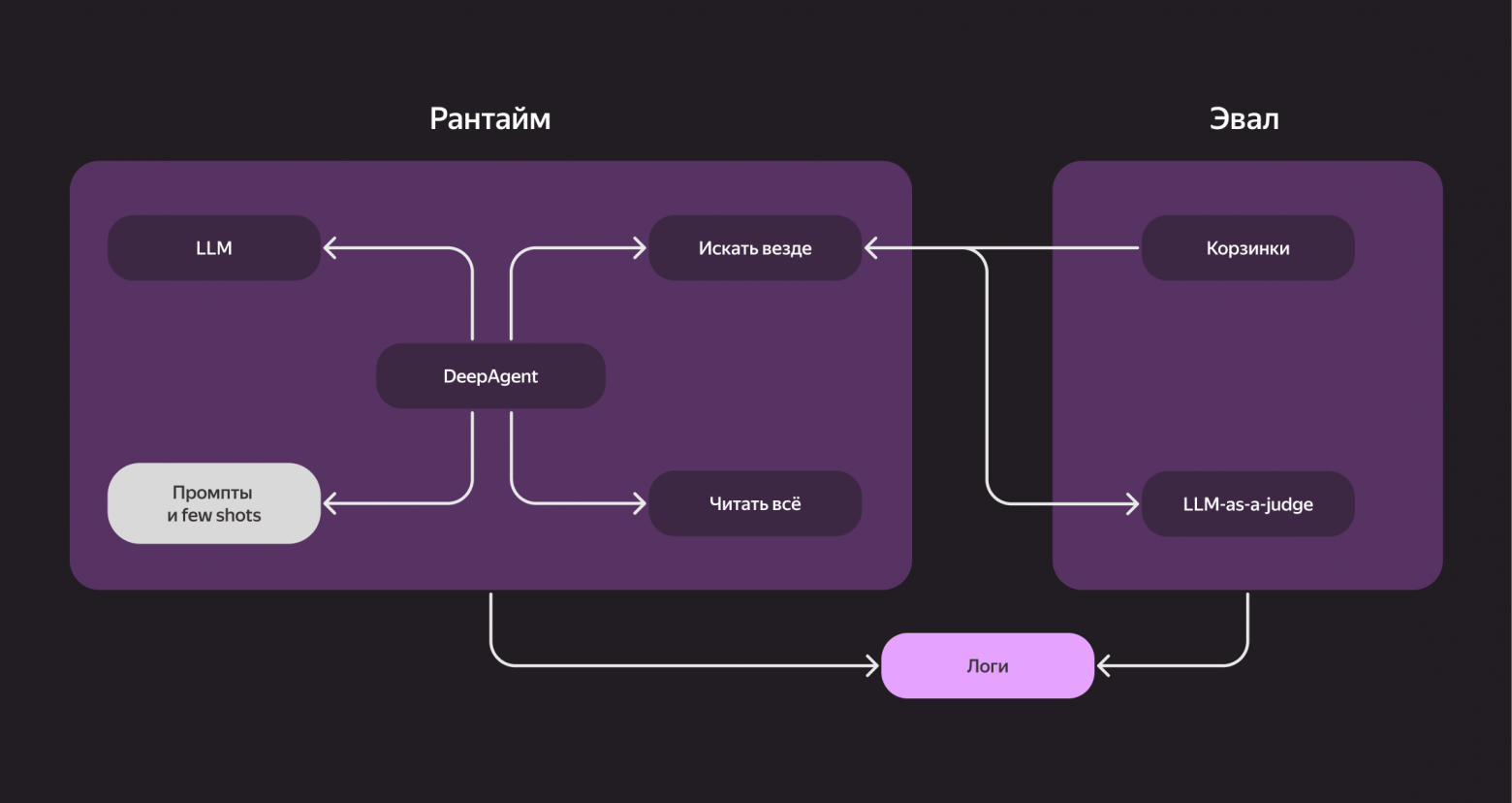
Главное правило — оценивать каждое изменение. Любое обновление должно сопровождаться проверкой качества, логированием всех запросов и отслеживанием ошибок. Если тул не сработал, агент не получил доступ к нужной странице или поиск завершился с ошибкой — всё это нужно видеть и исправлять. Именно в этих ошибках и живёт качество.
Мы добавили несколько таких шаблонных примеров (few shots) в системный промпт — и заметили улучшение. Конечно, это не панацея, но это отличный способ быстро поднять baseline.
И ещё один совет: логируйте абсолютно всё — каждый запрос, какие тулы вызывались, какие упали с ошибкой, был ли у агента доступ к странице, удалось ли ему прочитать документ и так далее Ошибки будут — и большая часть качества будет достигнута именно через их исправление. Примеры контролируемых ситуаций: тул не ответил, нет доступа к нужной странице, парсер упал, поиск вернул пустую выдачу. Все эти кейсы нужно фиксировать и потом устранять.
Одно из ключевых наблюдений команды во время работы — разница между подходами Tool Calling и Code Execution.
В классической схеме Tool Calling модель генерирует текст с явными вызовами тулов, например:<tool_call name="search" argument="как поднять сервис X">. Это работает, но медленно: требует нескольких итераций и тратит много GPU‑ресурсов.
Code Execution оказался гораздо эффективнее. Вместо того чтобы описывать вызовы словами, модель пишет один Python‑блок, внутри которого сама вызывает нужные функции — поиск, чтение, анализ. Всё выполняется за один проход, что сокращает время отклика и экономит токены. Качество тоже выше: модели реже галлюцинируют, потому что действуют в предсказуемом контексте.

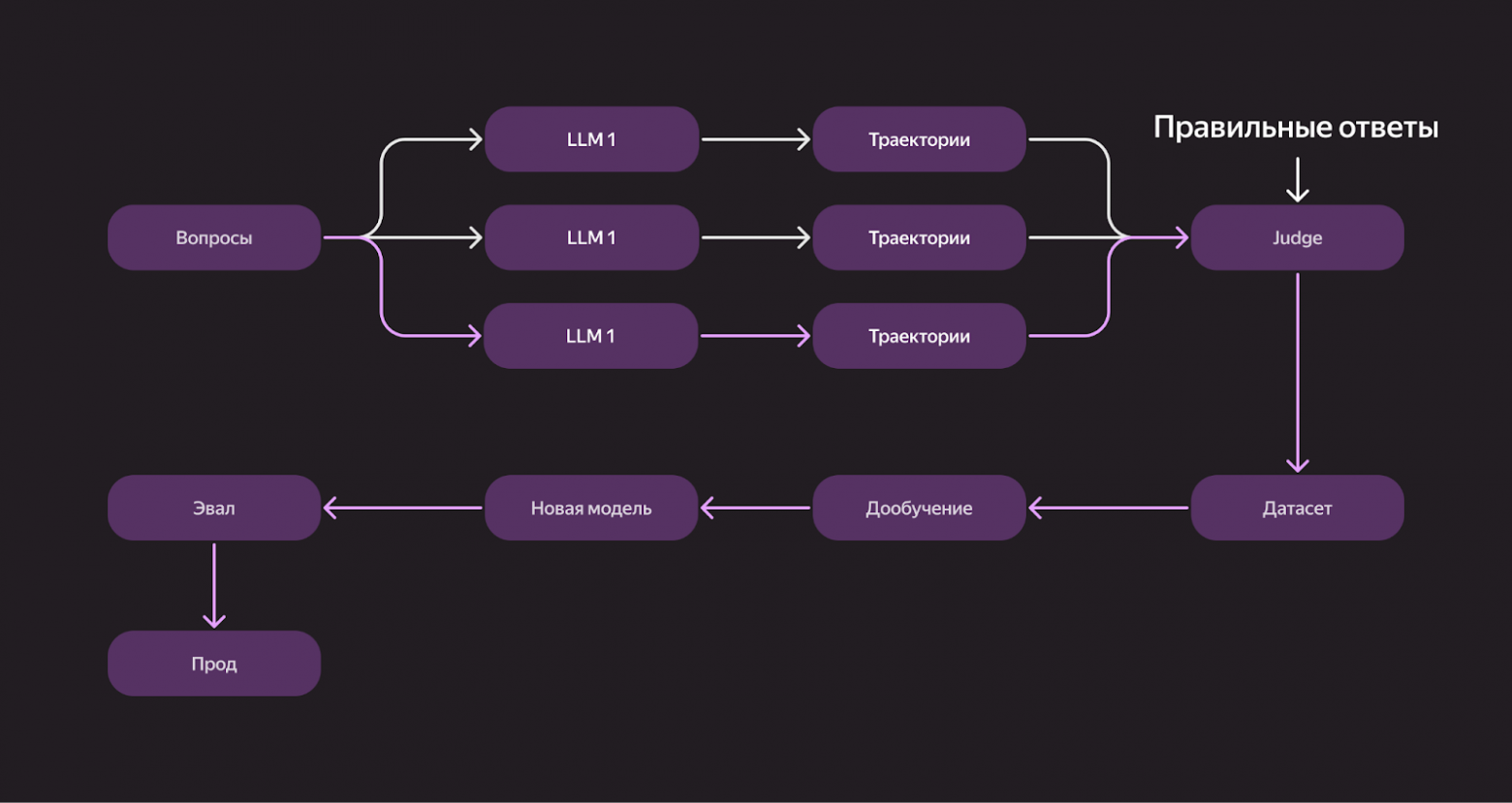
Когда улучшения с помощью тулов и few‑shot‑примеров перестали давать прирост, команда перешла к дообучению. Собрали большую корзинку с вопросами и прогнали их через разные LLM. Каждая модель выдала свои траектории — цепочки действий, которые привели к ответу. Эти траектории отправили в Judge вместе с правильными ответами. После оценки выбрали корректные решения и собрали из них датасет для дообучения. Новая модель, обученная на этих траекториях, показала лучшие результаты на эвале — и ушла в прод.
Одним из самых впечатляющих эффектов стало то, что DeepAgent научился читать код: он научился искать по регулярным выражениям и семантически, отвечая примерно на половину самых сложных вопросов о коде.
Раньше разработчики искали нужные фрагменты вручную или спрашивали коллег. Теперь просто обращаются к DeepAgent — это экономит часы времени каждому инженеру.
Уже сейчас разработчики компании используют DeepAgent для множества разных задач: скидывают текст ошибки, просят найти информацию по тикетам, спрашивают, как работает та или иная фича в сервисах или как им сделать те или иные действия во внутренней инфраструктуре. И на все эти запросы получают чёткий ответ.
Следующий шаг — научить агента читать не только код и документацию, но и всю внутреннюю инфраструктуру: Kubernetes, дашборды, графики, логи сервисов, Nirvana‑графы и другие инструменты. Если у разработчика что‑то не работает, он пишет в DeepAgent: «Вот ссылка, посмотри, где здесь ошибка, и скажи, что делать».
Агент сам прочитает логи, поймёт, в чём проблема, и предложит решение. В будущем сможет вносить изменения: перезапустить сервис или перевыкатить самого себя (надеемся, без катастроф).
Ещё одна из будущих задач — научить агента выполнять длинные сценарии: анализировать сотни тикетов, графиков или документов.
В итоге цель проекта проста: сделать единое окно для сотрудников. Туда можно будет прийти с любым вопросом — вместо того чтобы отвлекать тимлида или писать в общий чат: «А где у нас документация на сервис X?» или «Почему падает прод?»
Спасибо, что дочитали до конца! Поделитесь в комментариях, какие ИИ‑агенты вы используете в работе и есть ли какие‑то стандарты их использования в ваших компаниях.








-
Кому принадлежит Perplexity AI?
-
Как работает Perplexity AI?
-
Является ли Perplexity AI точным?
-
Может ли Perplexity AI помочь с конкретными задачами или вопросами?
-
Является ли Perplexity AI бесплатным сервисом?
-
Можно ли использовать Perplexity AI на мобильных устройствах?
-
Доступен ли Perplexity AI на разных языках?
-
Как начать работу с Perplexity AI?
Войти в Perplexity AI
- Появление нового подхода к поиску и обработке информации, который меняет наши представления о работе с знаниями. Perplexity AI — это не просто
Что такое Perplexity AI
- Perplexity AI — это не просто еще один чат-бот или поисковая система. Это интеллектуальный помощник, который сочетает в себе мощь искусственного
Регистрация Perplexity AI в России
- Perplexity AI — это современная поисковая система с искусственным интеллектом, которая помогает пользователям находить точные ответы на сложные