Валидация RAG с помощью RAGAS. Часть 1
Привет, меня зовут Вова Ловцов. Я дата-сайентист, работаю в команде Core DS в Cloud.ru, где мы занимаемся разработкой агентов, RAG-систем и других сопутствующих технологий.
Недавно мы запустили AI-помощника, который не только отвечает на вопросы по документации, разворачивает виртуальные машины и настраивает мониторинг за пользователей, но и помогает с SRE и FinOps. Под капотом это мультиагентная система, и один из ее ключевых компонентов — это RAG (Retrieval-Augmented Generation). Именно он отвечает за поиск информации и формирование понятных ответов.
Как понять, что RAG работает хорошо? Как его измерить, улучшить и выбрать лучшую конфигурацию? Обычные метрики вроде BLEU или ROUGE не всегда отражают качество ответа с точки зрения пользователя. Поэтому мы озадачились поиском автоматизированного и воспроизводимого решения и в итоге выбрали RAGAS — open source библиотеку для оценки RAG-систем. Но оказалось, что «из коробки» она работает далеко не идеально.
В этой части кратко расскажу про оценку и наш выбор исходя из внутренних особенностей. А в следующей — как подошли к адаптации RAGAS, какие проблемы встретили на пути и что придумали, чтобы их решить.

Зачем и как оценивать RAG и что решили мы
RAG-системы сегодня повсюду — от чат-ботов до поисковых ассистентов. Но они не просто про вопрос-ответ. Качество работы и финальных ответов зависит от каждого из этапов, в базовом исполнении это:
-
Поиск релевантного контекста (retrieval),
-
Генерация ответа на основе этого контекста (generation).
И если где-то происходит сбой, например, система не может найти нужные документы или генерирует вымышленный ответ, пользователь быстро потеряет доверие. Поэтому определить, на каком из шагов произошла ошибка — важная часть поддержки сервиса.
Впрочем, современные RAG системы зачастую содержат расширения, например:
1. Рерайтинг запроса пользователя.
2. Семантический поиск контекста (retrieval).
3. Полнотекстовый поиск контекста (retrieval).
4. Реранжирование фрагментов контекста (retrieval/reranking).
5. Генерация ответа на исходный запрос (generation).
6. Рефлексия и корректировка ответа (generation).
Так что при необходимости качество можно оценить после каждого шага поиска и генерации.
Вот несколько основных способов оценки RAG:
- классические метрики NLP (BLUE, ROUGE, Perplexity) и ранжирования (recall@k, ndcg). Эти метрики чаще требуют Ground Truth. К тому же не всегда хорошо коррелируют с человеческой оценкой.
- ручная разметка — эксперты оценивают ответы. Точно, но медленно, дорого и не масштабируется.
- LLM-as-a-judge — оценка ответов с помощью другой LLM. Быстро и автоматизируемо, но требует качественных промптов и метрик.

Мы выбрали автоматизацию, поскольку нужно было:
- генерировать синтетические тестовые данные (вопросы и ответы) на основе документации.
- оценивать RAG по нескольким метрикам: релевантность контекста, полноту ответа, достоверность и точность.
- обеспечить повторяемость, чтобы при изменении доки или модели можно было быстро перезапустить тесты.
Почему мы выбрали RAGAS
После анализа альтернатив (включая DeepEval, TruLens, LangChain Evals) мы остановились на RAGAS — open source библиотеке, которая:
- поддерживает генерацию синтетических данных на основе LLM.
- предоставляет метрики, не требующие ground truth.
- работает на основе графа знаний, что позволяет моделировать сложные связи между документами.
А вся эта функциональность в совокупности помогла бы нам генерировать разнообразные вопросы с высоким покрытием документов базы знаний, причем в автоматизированном режиме.

Граф знаний: что такое и почему он для нас важен
Одна из ключевых концепций RAGAS — граф знаний, который мы получаем из входных документов, применяя к ним набор трансформаций. Весьма удобно, что хоть пайплайн трансформаций и дефолтный, их можно переопределить и передать в метод построений графа. При этом набор готовых классов для пайплайн также уже предоставлен, остается только настроить параметры.
Немного расскажу, как всё это устроено.
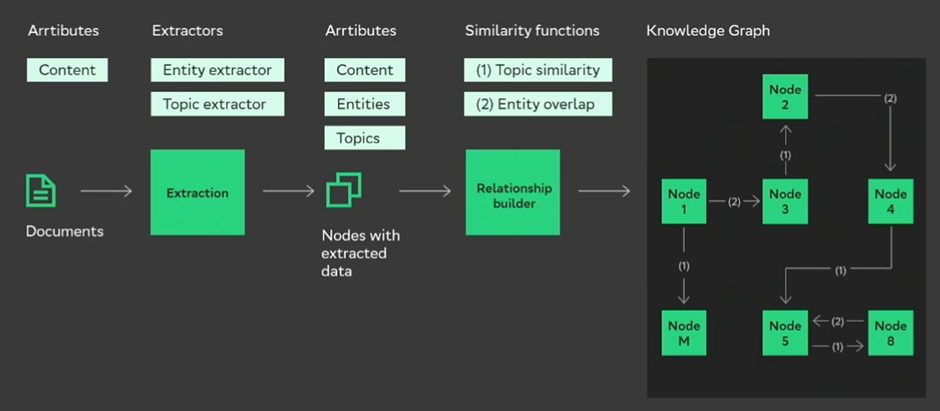
Среди трансформаций у нас есть экстракторы, которые просто извлекают данные — по сути выполняют задачу feature extraction. Из наших текстов извлекаются заголовки, эмбеддинги, сущности, темы и т. д.
Также есть один сплиттер — HeadlineSplitter. Как можно догадаться по названию, он не будет работать, если на предыдущем шаге не определили HeadlinesExtractor, ведь его задача — побить документ на чанки, основываясь на заголовках, которые он найдет. Также есть метод ограничения длины самого чанка количеством токенов.
Построение связей. У нас есть 4 (3, потому что первые два сути есть одно и то же) класса для построения связей. Это косинусная связь для суммаризации, перекрытие сущностей и jacquard similarity. На каждом этапе можно применять трансформацию не ко всем элементам нашего графа, а к определенным.
Есть и соответствующие фильтры: только к чанкам, только к документам и к документам с определенной длиной. А еще — custom node filter, про который я подробнее расскажу в следующей части.
Пример нашего pipeline
Как выглядит дефолтный pipeline? Первый шаг — headline extractor, который применяется к документам длиной не меньше 500 токенов. Потом мы разбиваем эти документы на чанки по headline splitter, берем summary и применяем custom node filter. Затем берем embedding от summary, извлекаем темы из chunk, извлекаем сущности из chunk, строим косинусные связи между документами и строим связи по перекрытию сущностей.
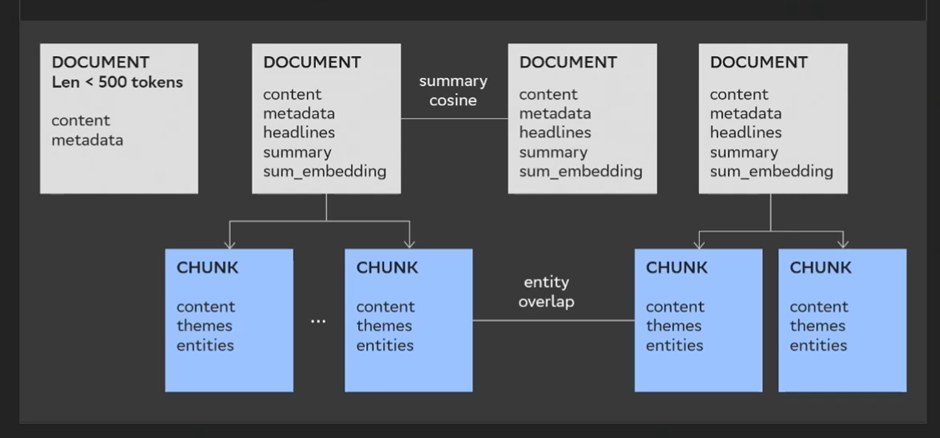
Разберем на примере. У нас есть четыре абстрактных документа, один из которых меньше, чем 500 токенов.
Шаг первый: мы получили заголовки. Ну, headlines.
Шаг второй: по этим headlines мы побили документы на чанки. У третьего слева документа (на скриншоте ниже) есть headlines, но при этом он пустой. Поэтому чанк у него не сформировался.
Шаг третий: мы берем summary у этих документов. И вот здесь как раз начинает работать custom node фильтр. В чем его идея? Он смотрит на summary родительского документа и на текущий chunk, а затем проверяет — есть ли какая-то связь или нет. И если это стандартный элемент навигации (например, типичный footer-header), то определяет, что в опросе добавлять его не нужно.
Шаг четыре: когда мы уже отсекли ненужный элемент — берем embedding от summary документов, извлекаем темы, извлекаем сущности, строим связь по косинусу эмбеддингов от summary, а затем строим связь по перекрытию сущностей для чанков.
И этот не сильно замысловатый подход, сильно помогает нам представить нашу базу знаний в оптимальном виде.
На этом извлечение информации из входных документов заканчивается, и мы переходим к генерации синтетических данных. Но об этом я подробно расскажу уже в следующей части ?








-
Кому принадлежит Perplexity AI?
-
Как работает Perplexity AI?
-
Является ли Perplexity AI точным?
-
Может ли Perplexity AI помочь с конкретными задачами или вопросами?
-
Является ли Perplexity AI бесплатным сервисом?
-
Можно ли использовать Perplexity AI на мобильных устройствах?
-
Доступен ли Perplexity AI на разных языках?
-
Как начать работу с Perplexity AI?
Войти в Perplexity AI
- Появление нового подхода к поиску и обработке информации, который меняет наши представления о работе с знаниями. Perplexity AI — это не просто
Что такое Perplexity AI
- Perplexity AI — это не просто еще один чат-бот или поисковая система. Это интеллектуальный помощник, который сочетает в себе мощь искусственного
Регистрация Perplexity AI в России
- Perplexity AI — это современная поисковая система с искусственным интеллектом, которая помогает пользователям находить точные ответы на сложные